Accelerating Data Retrieval in Retrieval Augmentation Generation (RAG) Pipelines using CXL
Introduction
RAG (retrieval augmented generation) has emerged as a powerful technique to customize LLMs for users and use cases beyond the model’s training set. However, there are multiple potential bottlenecks within a RAG pipeline, including, but not limited to, the following:
- CPU: Embedding generation
- GPU: LLM Inference
- Memory Capacity: Storing large datasets and embeddings in memory
- Memory Bandwidth: A limited number of DDR modules limits the throughput per CPU Core
- Storage IOPS: Data that needs to be retrieved from persistent storage
We investigated the feasibility of integrating Compute Express Link (CXL) memory into a RAG pipeline and the potential benefits of combining DRAM and CXL to improve pipeline performance. CXL is used to limit or completely avoid disk I/O and improve memory capacity and bandwidth.
The Magic of RAG is in the Retrieval
The real magic of RAG is in retrieving data to feed upstream into the generation part of the RAG pipeline. The figure below shows a naive RAG pipeline where the embedded data from the knowledge documents is stored in a single vector database. Data is retrieved when the user provides a question. The nearest neighbors from the vector database are retrieved and sent to the LLM prompt for processing.
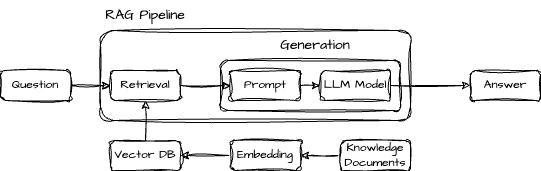
Figure 1: A naive RAG pipeline
RAG deployments perform best when the quality of the source content and the retrieval model’s ability to filter the large data source down to useful data points before feeding it to an LLM. Therefore, most of the development effort should focus on optimizing the retrieval model and ensuring high-quality data.
The role of the LLM in a RAG system is to summarize the data from the retrieval model’s search results, with prompt engineering and fine-tuning to ensure the tone and style are appropriate for the specific workflow. All the leading LLMs on the market support these capabilities.
LlamaIndex
Our goal was to use a pipeline built on preexisting, popular, easily implemented components to demonstrate the ease with which CXL could enhance workflows that have already been adopted or could be easily picked up by developers. For this purpose, we decided to use LlamaIndex as the RAG framework.
LLamaIndex Simple Composable Memory
RAG pipelines require “memory”. “RAG memory” is a dynamic data store of past information relevant to current and future queries, usually a vector database. A notable feature of LlamaIndex is its Simple Composable Memory objects, which combine multiple context sources into one component, allowing a RAG pipeline to have multiple memory sources.
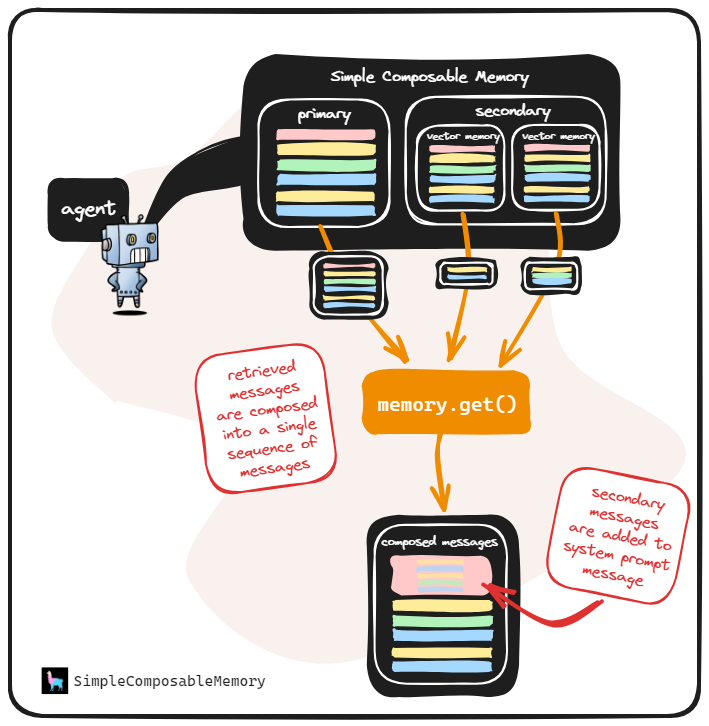
Figure 2: LlamaIndex Simple Composable Memory
This allows for the interesting possibility of easier integration of multiple separate databases into one pipeline: rather than having one massive database containing all of the (potentially heterogenous types of) context your pipeline must have access to, different types and segments of the data could easily be placed into different databases, then composed as context for a singular pipeline through composable memory.
The new RAG Pipeline
To illustrate this proof of concept and add CXL to the mix, we created our demo based on a custom RAG pipeline. Figure 3 shows the modified RAG pipeline using LlamaIndex and two separate Qdrant vector databases running locally as docker containers.
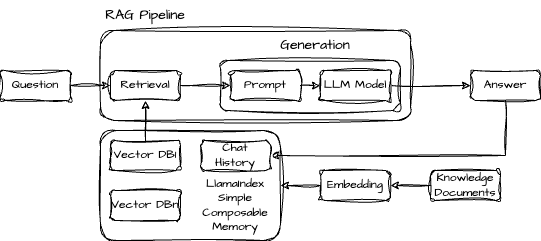
Figure 3: The updated RAG Pipeline showing LLamaIndex Simple Composable Memory
Figure 4 shows in more detail how DRAM and CXL are used.
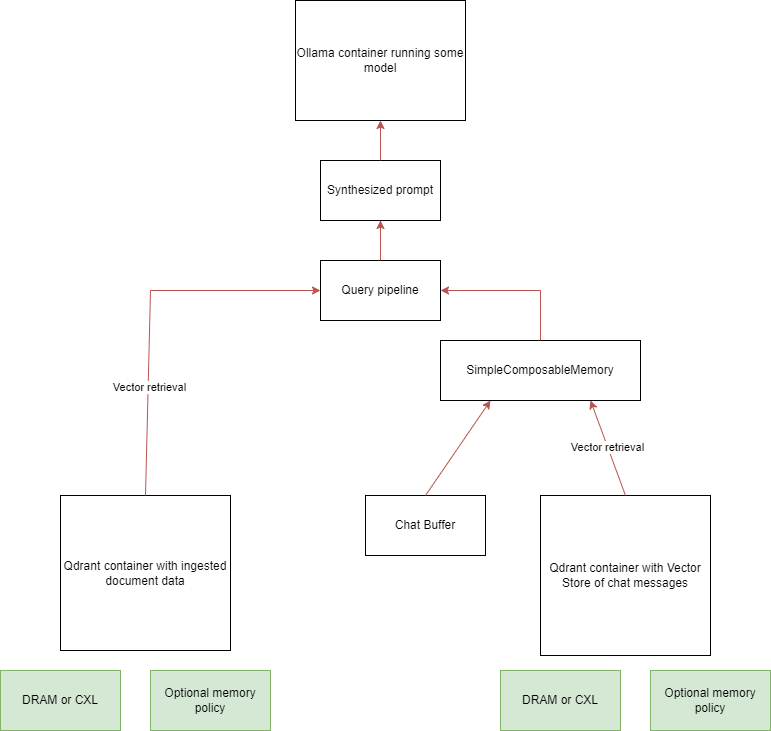
Figure 4: A detailed diagram showing the use of DRAM and CXL in the updated RAG pipeline
In total, there are three sources of context, all different from each other: documents (in our example, Wikipedia articles); the current chat buffer (i.e., the history of messages between the current user and the model within the ongoing session); and a large store of other messages (in our demo scenario, a store of what acts as past messages from all users who’ve interacted with the model). Embeddings created from the documents are in one Qdrant database and the past message store is represented by vectors stored in the second Qdrant database. LlamaIndex manages the chat buffer.
This pipeline successfully retrieves context from these multiple separate and heterogeneous context sources. Additionally, the databases can be bound to specific CPUs and NUMA nodes, allowing the most memory-intensive parts of the pipeline to be stored on DRAM, CXL, or both. We used MemVerge Memory Machine X (MMX) to manage the data placement and movement transparently so Qdrant and LlamaIndex didn’t need any code modifications. MMX has two memory policies - latency and tiering - that strategize data placement and movement based on the underlying hardware topology and memory characteristics to improve application performance.
Vector Database Benchmarking
The demo pipeline acts as proof of concept for two things: retrieving context from separate databases and integrating CXL into a pipeline. We focused on how CXL could affect one potential bottleneck area for pipelines running at a production level by benchmarking vector database performance with different memory configurations.
Setup
We ran our tests using VectorDBBench: A Benchmark Tool for VectorDB. More specifically, we ran the Search Performance Test option, which uses the Cohere dataset comprising 10 million vectors, each with 768 dimensions.
- Qdrant was used for all tests.
- The host system has 1024GB of DRAM (12 DIMMs) and one 128GB CXL memory device.
- DRAM-only databases were pinned to one NUMA node, which comprised 6 DIMMs and 512GB of DRAM.
- CXL-only databases were pinned to one NUMA node comprising the CXL card.
- For all tests, the databases were bound to the same CPU set within the same NUMA node (this being the node used for the DRAM-only tests, which is also as close as possible to the CXL node).
- DRAM and CXL tests used our Memory Machine’s QoS bandwidth tiering to interleave memory usage between DRAM and CXL at a specific ratio.
- The database is pinned to the same DRAM node as the DRAM-only tests in addition to the CXL node.
- A 9:1 DRAM:CXL interleaving ratio and 1024mb threshold size (meaning that any process on the machine using at least 1024 MB of memory was interleaved) were used.
- The Memory Machine Version is 1.5.0
For each memory configuration, tests were run twice. The first time, the Cohere dataset was loaded into the Qdrant database and benchmarks were run to warm up the database. The second time (referred to as preloaded), the embedded vectors that now existed in memory were benchmarked, i.e. the ingestion into the database was skipped.
Results
| Memory settings | Queries per second | Recall | Load duration (s) | Serial latency p99 (ms) |
|---|---|---|---|---|
| dram only | 619.7658 | 0.9531 | 21468.837 | 18.2 |
| cxl only | 93.3271 | 0.9545 | 22651.6481 | 30 |
| dram and cxl + QoS (9:1) | 696.6969 | 0.9542 | 21331.3823 | 49 |
| Memory settings | Queries per second | Recall | Load duration (s) | Serial latency p99 (ms) |
|---|---|---|---|---|
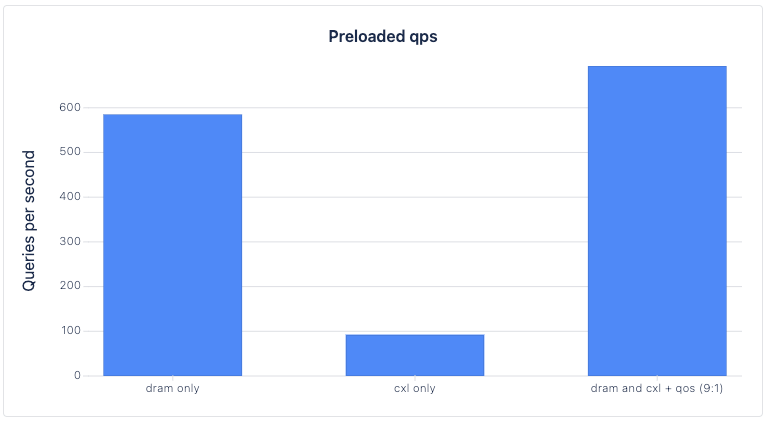
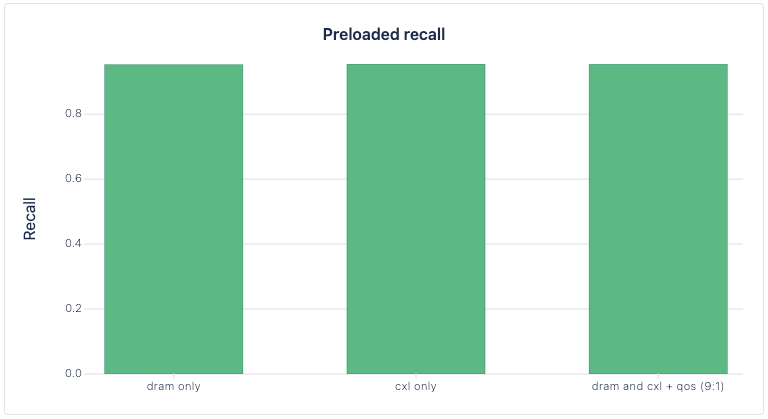
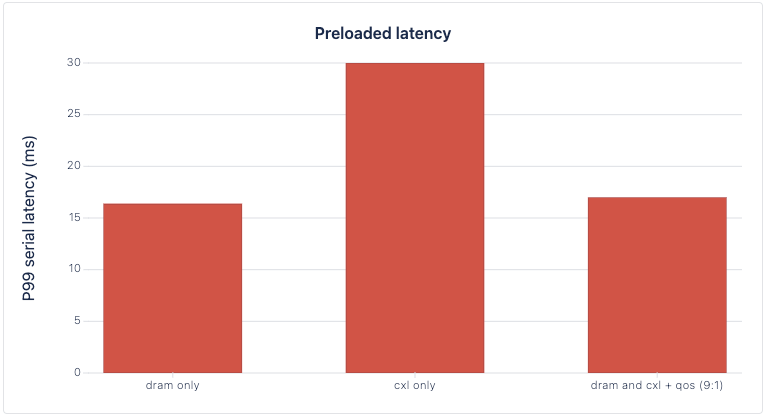
| dram only | 585.0216 | 0.9531 | preloaded | 16.4 |
| cxl only | 92.7315 | 0.9545 | preloaded | 30 |
| dram and cxl + Qos (9:1) | 693.4385 | 0.9542 | preloaded | 17 |
Conclusions
Combining the advantages of CXL with the more conventional use of DRAM in RAG pipelines had benefits. While the demo serves as a proof of concept that it is possible, the specific benchmarking of the vector databases shows that taking advantage of the increased bandwidth provided by CXL devices can speed up the execution of a RAG pipeline. Across DRAM only, CXL only, and DRAM + CXL interleaving, recall (a measure of vector database quality) was comparable. CXL only performed worse than the other options regarding QPS and Latency, which is expected given the dramatic difference in bandwidth and latency of a single CXL memory device vs size interleaved DDR modules.
Looking at the preloaded trials, DRAM + CXL’s QPS was 18.53% higher than DRAM-only’s, while its latency was only 3.65% higher than DRAM-only’s. Leveraging the additional bandwidth added by CXL memory can increase the max performance of a vector database while incurring minimal losses in latency, theoretically leading to an overall better performance for an entire RAG pipeline.
Future Research
There are still several questions that can be explored:
- The non-preloaded DRAM + CXL trial latency seems to be an outlier, but all the other metrics are consistent with other results. We need to investigate and better understand Qdrant and LlamaIndex internals to understand the bottlenecks. It could also help to benchmark Qdrant with larger datasets (the Cohere dataset takes about 32 GB of memory in total).
- It would be useful to test the effects of CXL on a massive pipeline setup that is more akin to production-level RAG. This would involve massive databases and potentially multiple instances of the same pipeline running simultaneously, further stressing the databases and increasing the importance of QPS.
- We could increase the total number of databases used by the pipeline from two to three, pin certain databases to DRAM and others to CXL rather than interleaving them all, and even consider distributed or pooled memory sources for databases.