
How Big Memory is Being Deployed by Server Vendors: Penguin Computing
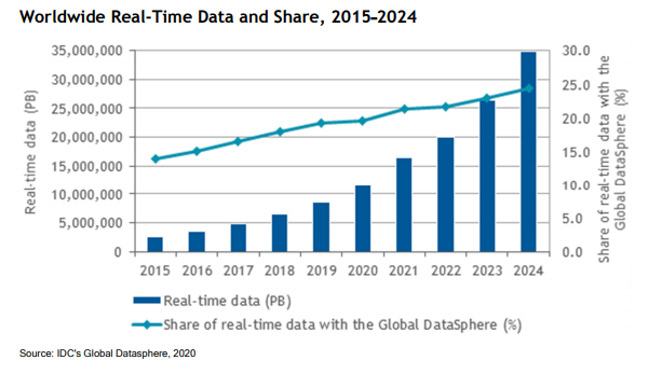
Penguin Computing is a leader in providing servers for scientific and business high-performance computing. For the fast-emerging class of real-time analytics and machine learning applications with massive data sets, running completely in-memory is critical to meeting their performance requirements. According to IDC, worldwide, data is growing at a 26.0% CAGR, and in 2024 there will be 143 zettabytes of data created. However, what people don’t know is that real-time data is growing much faster. Real time data was less than 5% of all data in 2015, and now is projected to comprise almost 30% of all data by 2024. IDC also projects that by 2021, 60-70% of the Global 2000 will have at least one mission-critical real-time workload. By 2021, 60-70% of the Global 2000 will have at least one mission-critical real-time workload.
Watch this Big Memory case study by Kevin Tubbs, PhD, of Penguin Computing. Kevin describes how the Facebook Deep Learning Recommendation Model (DLRM) needs terabytes of memory for embedded tables and how Optane PMEM and Memory Machine Software will enable Penguin to scale memory for DLRM, and across their data center, embedded, and wireless (IoT) businesses.